

2020-2021學年浙江省紹興市諸暨二中高一(下)期中信息技術試卷
發布:2024/4/20 14:35:0
一、選擇題(本大題共12小題,每小題2分,共24分)
-
1.在數據整理中2020/2/30屬于數據問題中的( )
組卷:4引用:1難度:0.5 -
2.下列關于大數據處理的說法,錯誤的是( )
組卷:4引用:5難度:0.5 -
3.下列關于Hadoop的功能說法錯誤的是( )
組卷:0引用:1難度:0.4 -
4.下列DataFrame常用函數語句及其對應解釋錯誤的是( )
組卷:0引用:2難度:0.5 -
5.文本數據處理的一般過程不包括( )
組卷:6引用:1難度:0.6
二、非選擇題(本大題共4小題,其中第13小題6分,第14小題6分,第15小題6分,第16小題8分,共26分)
-
15.學校對各班級的文藝匯演成績做了評分,并利用Excel軟件進行數據處理,部分界面如圖1所示。
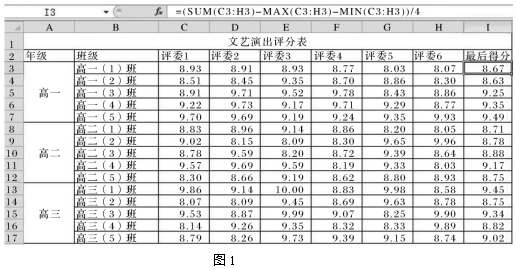
(1)用公式計算出各班級得分,可在I3單元格輸入公式,再利用自動填充得到其它班級得分,則I6單元格上的公式為。
(2)若將I3:I17單元格的數值小數位數設置為0,則I3單元格中的值。(單選:填字母)
A.變大
B.不變
C.變小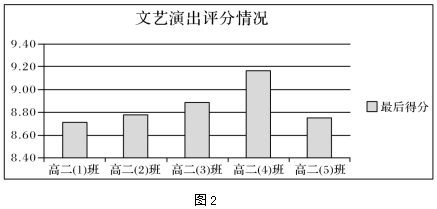
(3)根據數據表中的數據制作的圖表如圖2所示,創建該圖表的數據區域為。
(4)若只對“高二”年級以“最后得分”為主要關鍵字降序排序,則排序時選擇的數據區域是。
(5將各年級最后得分最高的班級設為該年級的一等獎,下列方法可得到高二年級一等獎班級的是。(多選,填字母)
A.選擇區域B8:I12,再按“列I”為關鍵詞進行降序排序后,該區域的第1條記錄為高二年級一等獎班級
B.先篩選出“班級”開頭是“高二”的記錄,再篩選出“最后得分”為最大1項的記錄,篩選結果即為高二年級一等獎班級
C.先篩選出“最后得分”為最大1項的記錄,再篩選出“班級”包含“高二”的記錄,篩選結果為高二年級一等獎班級
D.先按“最后得分”升序排序,再篩選出“班級”包含“高二”的紀錄,最后一條記錄為高二年級一等獎班級組卷:0引用:1難度:0.3 -
16.某市普通高中選課數據如圖1所示,學生從地理、化學、生物等科目中選擇三門作為高考選考科目,“1”表示已選擇的選考科目。使用 Python編程分析每所學校各科目選考的總人數、全市各科選考總人數及其占比,經過程序處理后,保存結果如圖2。
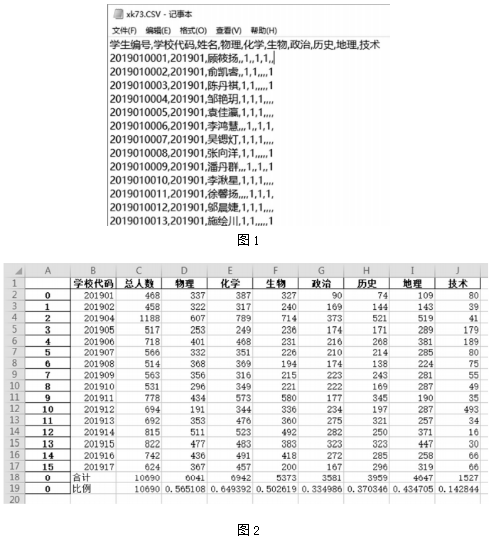
實現上述功能的 Python程序如下:
import pandas as pd
import itertools
#讀數據到pandas的 DataFrame結構中
df=① (”xk73.jye.ai”,sep=‘.’,header=‘infer’,encoding=‘utf-8’)
km=[‘物理’,‘化學’,‘生物’,‘政治’,‘歷史’,‘地理’,‘技術’]
zrs=len(df.jye.ai)
#按學校分組計數
sc=df.groupby(‘② ’,as_index=False).count( )
#對分組計數結果進行合計,合計結果轉換為 DF結構并轉置為行
df_sum=pd.DataFrame(data=sc.jye.ai ( )).T
df_sum[‘學校代碼’]=‘合計’
#增加“合計”行
result=sc.jye.ai(df_sum)
#百分比計算
df_percent=df_sum
df_percent[‘學校代碼’]=‘比例’
for k in km:
per=df_percent.at[0,k]/zrs
df_percent[k]=per
#增加“百分比”行
result=result.jye.ai(df_percent)
#刪除“姓名”列
result=③
#修改“學生編號”為“總人數”
result=result.jye.ai(columns={‘學生編號’:‘總人數’})
#保存結果,創建 Excel文件.生成的 Excel文件
result.to_excel(“學校人數統計.xlsx”)
(1)請在橫線處填入合適的代碼。
①②③
(2)加框處語句的作用是。組卷:6引用:1難度:0.3